4. SHAP vs fANOVA — 무엇이 다른가¶
작성 중
이 페이지는 현재 작성 중입니다.
지금까지 fANOVA의 직교 분해(2절)와, 그것을 트리 모형에 사후 적용하는 purification(3절)을 살펴보았다. 그렇다면 실무에서 훨씬 많이 쓰이는 SHAP은 같은 문제를 어떻게 처리하는가? 이 절에서는 두 프레임워크의 근본적 차이를 정리하고, 각각이 적합한 상황을 비교한다.
핵심 차이: 분배 vs 분리¶
SHAP과 fANOVA는 모두 "변수별 기여"를 구하지만, 교호작용(interaction)을 처리하는 방식이 근본적으로 다르다. 한 문장으로 요약하면: SHAP은 교호작용을 변수들에게 나눠주고, fANOVA는 교호작용을 별도의 항으로 분리한다.
| SHAP | Functional ANOVA | |
|---|---|---|
| 사상(思想) | 분배(distribute) | 분리(decompose) |
| 교호작용 처리 | 관여한 변수들에게 균등 분배 | 별도의 교호작용 항으로 분리 |
| 결과물 | 변수당 하나의 숫자 \(\phi_j\) | 주효과 \(f_j\) + 교호작용 \(f_{jk}\) + ... |
| 해석 단위 | 개별 샘플 (local) | 함수 전체 (global), 조건부로 local도 가능 |
| 분포 의존성 | background distribution에 의존 | \(\mathbb{P}(X)\)에 의존 |
| 공통 한계 | 분포 선택이 값을 바꾼다 | 분포 선택이 해석을 바꾼다 |
이 표만으로는 차이가 와닿지 않을 수 있다. 구체적인 예시로 각 항목이 실제로 무엇을 의미하는지 확인하자.
교호작용은 어디로 가는가?¶
두 변수 \(X_1\)(소득)과 \(X_2\)(부채)가 교호작용을 일으킨다고 하자. 즉, 소득이 높고 부채가 낮을 때 부도 확률이 비선형적으로 급감하는 시너지 효과가 있다.
SHAP의 처리:
SHAP은 교호작용의 기여분을 관여한 변수들에게 반씩 나눠준다. Shapley Value의 대칭성 공리에 의한 것이다:
이렇게 하면 모든 기여가 변수 수만큼의 숫자로 깔끔하게 떨어진다. 개별 고객의 예측을 설명하기에는 편리하다. "이 고객의 부도 확률이 높은 이유는 소득 -0.3, 부채 +0.5, ..." 식으로 말할 수 있으니까.
하지만 대가가 있다. 교호작용이 분배되어 녹아들기 때문에, 소득이 동일한 두 차주라도 소득의 SHAP 값이 다를 수 있다.
차주 A: 소득 5,000만 원, 부채 500만 원 → 소득의 SHAP = -0.8 (부도↓ 크게 기여)
차주 B: 소득 5,000만 원, 부채 2억 원 → 소득의 SHAP = -0.2 (부도↓ 약하게 기여)
소득은 같은데 SHAP 값이 다르다. 차주 A에서는 "고소득+저부채" 시너지가 크게 작동하여 소득에 분배되는 교호작용 기여분이 크고, 차주 B에서는 시너지가 약해서 소득의 몫이 줄어든다.
이것이 SHAP이 태생적으로 local(개별 샘플) 해석일 수밖에 없는 이유다. 소득 변수의 SHAP 값이 샘플마다 달라지니, "소득의 효과는 이렇다"는 global 진술을 할 수 없다.
SHAP의 교호작용 함정
교호작용이 변수별 숫자 안에 녹아들어 버리기 때문에, SHAP 값만 보고는 교호작용이 존재하는지, 얼마나 강한지 알 수 없다. 같은 변수의 SHAP 값이 샘플마다 크게 요동치면 "교호작용이 있을 수도 있겠다"고 짐작할 수는 있지만, 그것이 어떤 변수와의 교호작용인지는 SHAP 값 자체로는 식별할 수 없다.
실무에서 mean(|SHAP|)로 변수 중요도를 구하는 것이 관행이지만, 이 숫자에는 주효과와 교호작용이 뒤섞여 있다.
fANOVA의 처리:
fANOVA는 교호작용을 분배하지 않고, 별도의 항으로 분리한다. 직교 제약 조건(2절, 식 2~5)에 의해 각 항이 유일하게 결정된다:
- \(f_1(X_1)\): 순수하게 소득만의 효과
- \(f_2(X_2)\): 순수하게 부채만의 효과
- \(f_{12}(X_1, X_2)\): 소득과 부채의 순수 교호작용 — 주효과로는 설명할 수 없는 시너지
소득이 동일한 두 차주에서 \(f_1\)(소득의 순수 효과)은 항상 같다. 차이가 있다면 그것은 \(f_{12}\)(교호작용)에 명시적으로 나타난다 — 숨겨지지 않는다.
왜 이 차이가 중요한가 — 신용평가 실무 관점¶
규제 심사(모형검증)에서 심사역이 묻는 질문:
"소득 변수의 효과가 단조적(monotonic)인가?"
이 질문에 SHAP으로 답하면:
- 소득의 SHAP 값에 교호작용 기여분이 섞여 있으므로, 특정 구간에서 비단조적 패턴이 나타날 수 있다
- 이것이 소득 자체의 비단조성인지, 다른 변수와의 교호작용 때문인지 구분할 수 없다
- Lengerich et al. (2020)의 COMPAS 실험에서, XGB의 SHAP 기반 주효과 부호가 다른 모형과 반대로 나타나는 사례가 보고되었다
fANOVA(+ purification)로 답하면:
- 주효과 \(f_1(X_1)\)은 순수하게 소득만의 효과이므로, 단조성 여부를 정확히 판단할 수 있다
- 비단조적 패턴이 있다면 그것은 교호작용이 아니라 소득 자체의 비선형성이다
공통 한계 — 분포 선택이 해석을 바꾼다¶
SHAP과 fANOVA는 접근 방식이 다르지만, 결과가 분포에 의존한다는 근본적 한계를 공유한다. 어떤 방법론을 쓰든, "이 변수의 효과"를 정의하려면 "다른 변수를 어떻게 처리할 것인가"를 결정해야 하고, 그 결정이 곧 분포 선택이기 때문이다.
SHAP — 알고리즘에 따라 분포 의존성이 다르다:
- TreeSHAP (트리 모형 전용, 실무에서 주로 사용): 변수가 coalition에 포함되지 않을 때, 해당 변수의 split 노드에서 양쪽 가지를 모두 따라가면서 훈련 시 각 가지로 흘러간 샘플 비율로 가중평균을 낸다. 별도의 background 데이터셋이 필요 없고, 분포가 트리 구조에 이미 고정되어 있으므로 사용자가 선택할 여지가 없다.
- KernelSHAP (모형 불문 범용): 별도의 background 데이터셋을 지정해야 한다. 훈련 데이터 전체를 쓸 것인가, k-means 대표점을 쓸 것인가, 특정 하위 집단만 쓸 것인가 — 선택에 따라 SHAP 값 자체가 달라진다.
fANOVA — 훈련 데이터에서 자연스럽게 결정되지만, 희소 구간에서 주의가 필요하다:
fANOVA의 기대값 계산과 purification의 가중평균은 모두 분포 \(\mathbb{P}(X)\)에 의존한다. 실무에서는 훈련 데이터의 bin별 샘플 비율(empirical distribution)을 가중치로 사용하는 것이 자연스럽다 — 별도로 "분포를 정의"하는 단계가 아니라, 트리 학습 시 이미 결정된 bin과 샘플 수를 그대로 쓰는 것이다.
다만, 희소 구간(예: DTI > 300%에 샘플이 3명뿐인 경우)에서 가중치가 극도로 작아져 결과가 불안정해질 수 있다. Lengerich et al. (2020)은 이 문제에 대해 세 가지 가중 방식을 비교했다:
| 가중 방식 | 정의 | 특성 |
|---|---|---|
| Uniform | 모든 bin에 균등 가중 | 희소 구간의 영향이 과대 반영될 수 있음 |
| Empirical | 훈련 데이터 빈도 기반 | 데이터가 많은 구간의 해석이 안정적, 희소 구간은 불안정 |
| Laplace | Uniform + Empirical 혼합 | 절충안 — 희소 구간의 극단적 왜곡을 완화 |
세 가지 가중 방식으로 purification을 수행하면, purified main effect curve의 모양 자체가 달라진다. 즉, "소득 변수의 순수 효과"라는 것 자체가 분포 선택에 따라 다른 답을 줄 수 있다.
해석의 절대적 정답은 없다
이것은 fANOVA나 SHAP의 결함이 아니라, 해석 자체의 본질적 한계다. "이 변수의 효과"를 정의하려면 "다른 변수를 어떻게 처리할 것인가"를 반드시 결정해야 하고, 그 결정이 곧 분포 선택이다. 어떤 방법론이든 이 선택에서 자유로울 수 없다.
실무적 권장: 훈련 데이터의 empirical distribution을 기본으로 사용하되, 희소 구간의 해석은 별도로 검증한다.
fANOVA로 개별 샘플을 설명할 수 있는가?¶
fANOVA는 global 해석 도구이고, 개별 샘플 설명은 SHAP의 영역이라고 흔히 생각한다. 하지만 이것은 절반만 맞다. 교호작용 차수를 제한한 모형에서는 fANOVA가 오히려 더 정직한 개별 설명을 제공할 수 있다. 차수가 높아지면 fANOVA의 한계가 드러나고, 그때 SHAP이 필요해진다.
2-way까지 제한된 모형 — fANOVA가 더 정직하다¶
GA\(^2\)M(EBM)이나 depth-2 트리처럼 교호작용을 2-way로 제한한 모형에서는, 개별 고객의 예측을 component별로 직접 제시할 수 있다:
| component | 값 | 의미 |
|---|---|---|
| \(f_0\) | +0.1 | 전체 평균 |
| \(f_{\text{소득}}(5000)\) | -0.3 | 소득의 순수 효과 |
| \(f_{\text{부채}}(2000)\) | +0.5 | 부채의 순수 효과 |
| \(f_{\text{소득,부채}}(5000, 2000)\) | -0.4 | 소득×부채 순수 교호작용 |
| 합계 | -0.1 | 이 고객의 예측값 |
교호작용을 변수에 나눠줄 필요 없이, 별도의 설명 항목으로 그대로 제시하면 된다. \(f_{12}\)는 2차원 heatmap으로 시각화도 가능하다. 이 방식은 SHAP보다 더 정직한 설명이다 — 교호작용이 숨겨지지 않고, 무엇이 주효과이고 무엇이 교호작용인지 명확히 구분되니까.
EBM이 이 전략을 쓴다. 교호작용을 2-way까지만 허용하고 (GA\(^2\)M의 "²"이 그 뜻이다), 그 중에서도 FAST 알고리즘으로 유의미한 pair만 선별한다. 변수 20개 모형이라면:
- main effect: 20개
- 선별된 2-way interaction: 10~20개
- 총 30~40개 항 → 충분히 제시 가능
3-way 이상 — fANOVA의 한계가 드러난다¶
depth가 깊어져서 \(X_1, X_2, X_3\)가 혼재된 3-way interaction이 나타나면, 두 가지 문제가 동시에 발생한다.
시각화의 벽: 2-way interaction \(f_{12}(x_1, x_2)\)는 heatmap(2차원 그림)으로 직관적으로 보여줄 수 있다. 하지만 3-way interaction \(f_{123}(x_1, x_2, x_3)\)는 3차원 텐서다. 이것을 시각화하려면 3D 등고선, 또는 \(x_3\)를 고정하고 2D slice를 여러 장 그려야 한다. 직관적 이해가 급격히 어려워진다.
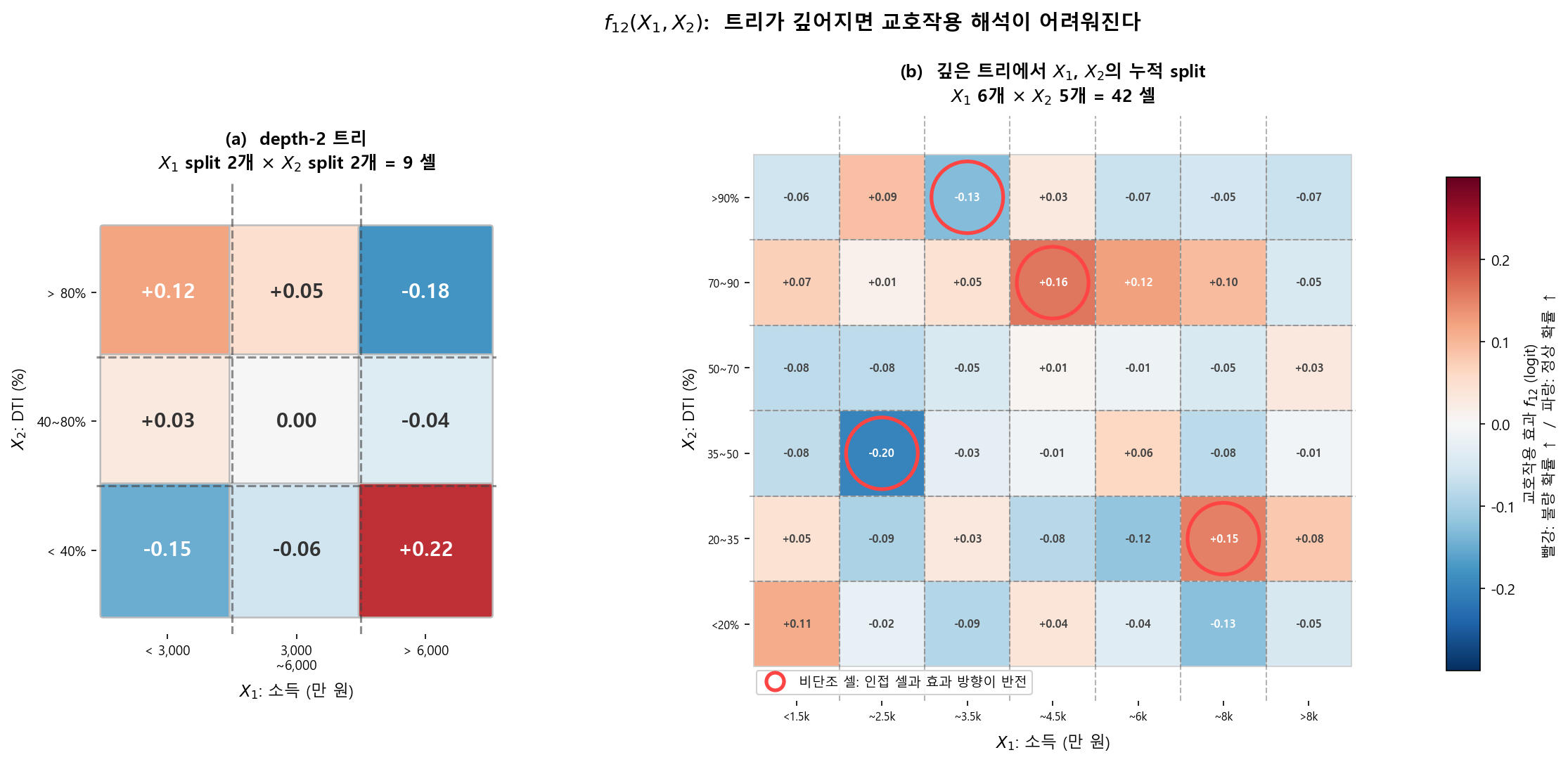
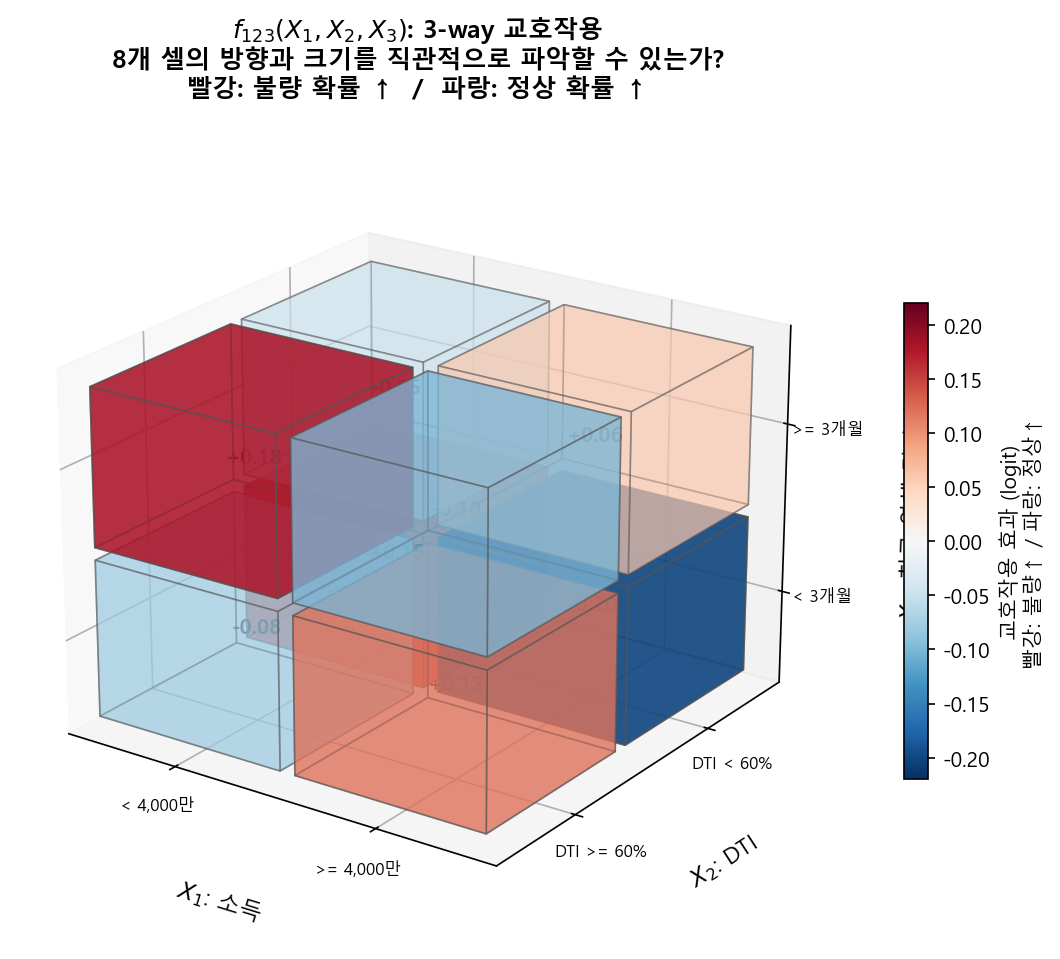
항 수의 폭발: 변수 20개에서 가능한 interaction 수:
| 차수 | 조합 수 | 시각화 |
|---|---|---|
| 2-way | \(\binom{20}{2} = 190\) | heatmap (2D) |
| 3-way | \(\binom{20}{3} = 1{,}140\) | 3D 텐서 → 사실상 불가 |
| 4-way | \(\binom{20}{4} = 4{,}845\) | 불가 |
3-way만 허용해도 1,140개의 interaction 항이 가능하다. 이 중 유의미한 것만 선별하더라도, 하나하나의 해석 자체가 어렵다 (3차원을 직관적으로 이해하기 힘드니까). 항 수의 문제와 개별 항의 이해 가능성 문제가 동시에 발생한다.
이때 SHAP이 빛을 발한다: 교호작용 차수가 아무리 높아도 변수당 숫자 하나로 요약해주므로, depth-6 XGBoost 같은 블랙박스에서도 개별 샘플 설명이 가능하다. 교호작용 정보가 숨겨지는 대가를 치르지만, 3-way 이상에서는 그 교호작용을 어차피 해석할 수 없으니 합리적 트레이드오프다.
참고 — "설명 가능한 depth 제한": depth가 5 이상이더라도, 변수 조합을 강제로 2-way pair로만 구성하면 각 pair는 2D heatmap으로 표현할 수 있다. 핵심은 트리의 depth가 아니라 하나의 interaction 항에 관여하는 변수 수다. EBM이 2-way로 제한하는 것은 바로 이 이유 — 2차원까지는 그림으로 보여줄 수 있고, 3차원부터는 안 되기 때문이다.
정리¶
| 교호작용 차수 | 개별 샘플 설명 | 시각화 | 대표 모형 |
|---|---|---|---|
| 없음 (GAM) | 변수당 1개 숫자 | 1D curve | depth-1 GBM |
| 2-way | main + interaction 별도 제시 | 2D heatmap | EBM (GA\(^2\)M) |
| 3-way 이상 | 항이 너무 많고, 각 항도 이해 어려움 | 3D 이상 → 비현실적 | XGBoost depth-3+ |
| 블랙박스 (제한 없음) | fANOVA 비현실적 → SHAP | — | XGBoost depth-6 |
fANOVA는 "개별 샘플 설명에 부적합"한 것이 아니라, "interaction 차수가 높아지면 설명 항이 폭발하고 시각화가 불가능해진다"는 것이 정확한 한계다. 2-way로 제한한 모형에서는 SHAP보다 fANOVA가 더 정직하고 유익한 개별 설명을 제공할 수 있다.
요약¶
| SHAP | fANOVA | |
|---|---|---|
| 강점 | 변수 수·interaction 차수 무관하게 변수당 1개 숫자 | 교호작용을 분리해서 보존 → 순수 효과 식별 |
| 약점 | 교호작용이 숨겨짐 → 무엇이 interaction인지 모름 | 고차 interaction에서 항 수 폭발 + 시각화 불가 |
| 적합한 질문 | "이 고객은 왜 거절되었나?" (블랙박스) | "이 변수의 역할은?" (global) + "이 고객은?" (2-way 제한 시) |
참고문헌¶
| 문헌 | 내용 |
|---|---|
| Lundberg & Lee (2017) | SHAP 원논문 (NeurIPS) |
| Lengerich, Tan, Chang, Hooker, Caruana (2020) | Purification 알고리즘 (AISTATS) — COMPAS 실험 |
| Molnar (2023+) | Interpretable ML Book — Ch.22: Functional Decomposition |